
做公司调研这件事,到底有多痛苦?
你随便抓一个投资人问,最头疼的工作是什么,“做尽调”肯定排前三。
不是不想做,是太他妈慢了。一家中等规模的科技公司,信息散落在几十个地方:官网、LinkedIn、Crunchbase、新闻稿、财报、行业报告、社交媒体……要整理出一份像样的公司画像,至少得花 3-5 天。
更烦的是幻觉问题。
同名公司怎么办?北京有个”云途科技”,深圳也有个”云途科技”,AI 怎么知道你要查的是哪一家?官网写着”行业领先”,真实市场份额到底是 5% 还是 50%?这些信息混在一起,人工核实的工作量巨大。
这就是 Guy Hartstein 的真实痛点。
他是 Tavily 的产品经理,每天都在和 AI 搜索打交道。但轮到自己查一家公司时,依然要打开十几个标签页,手动复制粘贴,再整理成文档。
“既然我们在做 AI 搜索,为什么不能做一个专门做公司研究的 Agent?”
一个周末,他打开 VS Code,开始了这个 side project。
从 prototype 到被公司收编,只用了两个月

Guy 并不是 AI 新手。加入 Tavily 之前,他做过软件工程师,也创过业。2025 年 2 月进 Tavily 后,负责 web 基础设施层的产品工作。天天跟 AI Agent 技术栈打交道,他知道这些东西能干什么、不能干什么。
但他真没想过,这个周末写的小工具,会改变自己的职业轨迹。
第一个版本很简陋:一个 Python 脚本,输入公司名字,输出一份 Markdown 报告。核心技术栈是 LangGraph,LangChain 团队推出的多智能体框架,专门用来构建复杂工作流。
“LangGraph 最吸引我的地方,是它既有工作流的确定性,又能保持灵活性。“Guy 后来在技术博客里写,“传统的确定性工作流像火车轨道,必须按预设路线走;纯动态的智能体像无头苍蝇,可能到处乱撞。LangGraph 让你在关键节点设置检查点,同时在节点之间保留决策空间。”
这个设计理念,直接影响了 Company Research Agent 的架构。
第一个版本出来后,Guy 发给几个做投资的朋友试用。他们的反馈出奇一致:“比我之前用的工具好太多了。”
好在哪里?
不是信息更多,是更准确。
当时市面上的 AI 研究工具,比如开源社区大名鼎鼎的 GPT Researcher,擅长的是通用研究。你给一个大话题,它全网搜索,生成一份综合报告。但公司研究有个特殊需求:必须精确到具体实体。
同名公司问题怎么解?官网信息和第三方数据如何交叉验证?这些细节,通用工具处理不好。
Guy 的解决方案是一个叫 Grounding 的技术。
Grounding:解决 AI 幻觉的”定海神针”

Grounding 这个词,在 AI 领域不算新。但 Guy 的应用方式,说明他真的理解这个问题。
流程是这样的:
用户输入公司名称和官网 URL,系统先用 Tavily Extract 抓取官网内容,建立”ground truth”(基准事实)。然后用这个基准去筛选和验证其他来源的信息。遇到同名公司时,通过内容相似度聚类,自动识别正确的实体。最后生成报告时,所有结论都有可追溯的来源。
“关键不是搜到多少信息,是确保每条信息都锚定在一个可信的基准上。”
这个设计解决了 AI 研究中最棘手的两个问题:
同名实体歧义。北京云途科技和深圳云途科技,在搜索引擎里可能返回相似的结果。但有了官网作为 ground truth,系统可以通过内容聚类自动区分。如果聚类结果不明确,还可以引入人工验证环节。
来源可信度。很多 AI 工具的问题是,给你一个结论,但你不知道这个结论从哪来的。Grounding 机制要求,每条写入报告的信息,都必须能通过 URL 追溯到原始来源。这不是什么技术创新,是产品设计的底线思维。
Guy 还注意到,研究和写作是两个不同的认知任务,用同一个模型做,既不经济,效果也不好。
于是他设计了一个双模型架构:
Gemini 2.5 Flash 负责研究综合。它的上下文窗口大,擅长在海量信息中提炼关键洞察。
GPT-5.1 负责报告格式化。它遵循指令精确,输出的 Markdown 结构规整、格式一致。
“让专业的人做专业的事。“这句话用在 AI 模型上,同样适用。
8 个智能体的流水线,是怎么工作的?
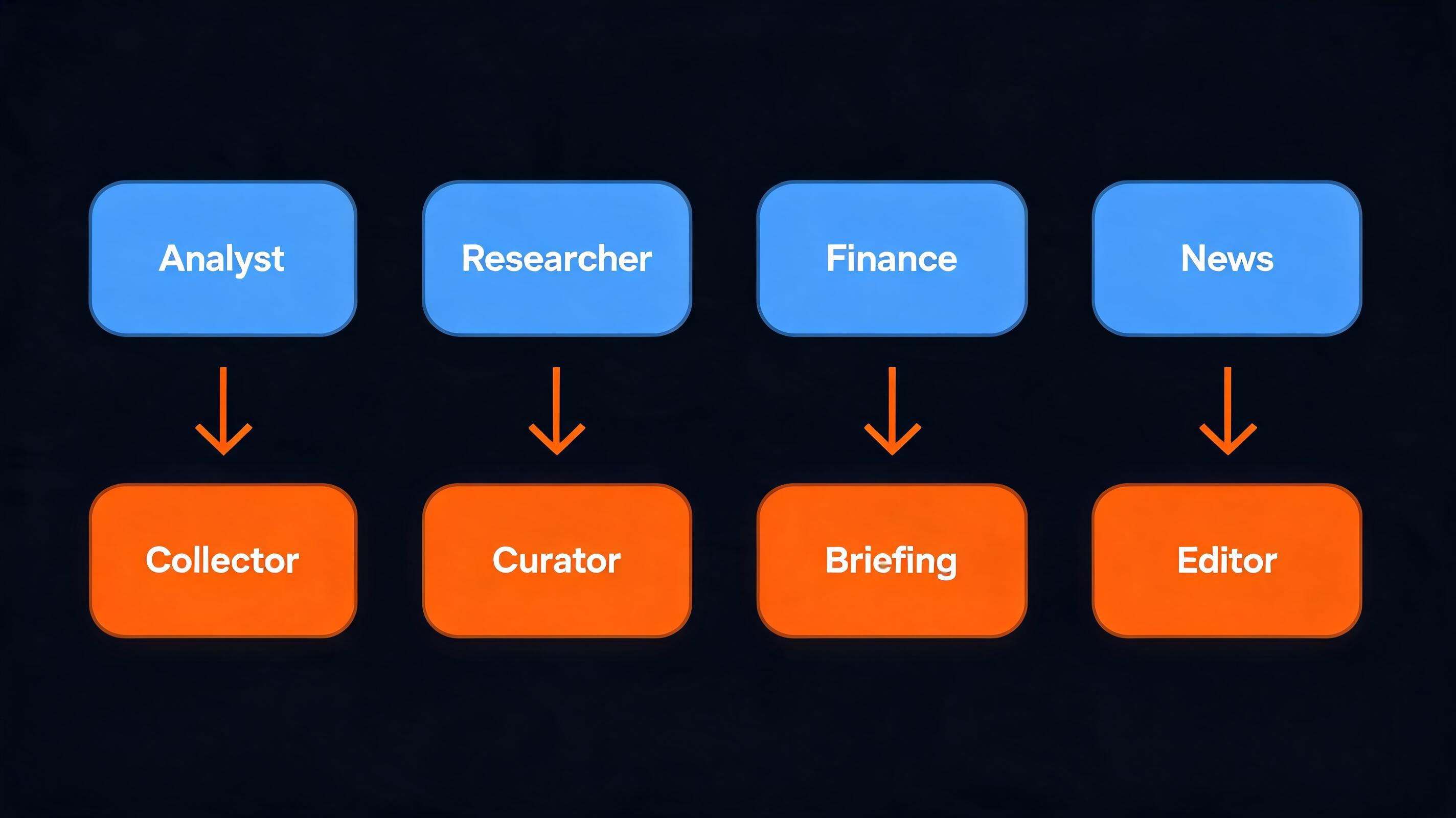
Company Research Agent 的核心,是一个由 8 个智能体组成的流水线。
不是 8 个独立的 Agent 各干各的,是一个有向图结构。每个节点有明确的输入输出,节点之间通过状态传递信息,整个流程可以可视化、可调试、可扩展。
信息收集阶段有 4 个智能体:
CompanyAnalyzer(公司分析员)研究核心业务、产品、团队结构。
IndustryAnalyzer(行业分析员)分析市场定位、竞争格局、行业趋势。
FinancialAnalyst(财务分析员)收集财务指标、融资历史、估值信息。
NewsScanner(新闻扫描员)抓取近期新闻、动态、舆情。
这 4 个智能体并行工作,各自负责一个信息维度。它们不是简单的搜索加摘要,而是会根据研究目标,动态生成子问题,再用 Tavily Search 精准检索。
内容处理阶段也有 4 个智能体:
Collector(收集器)聚合 4 个分析员的数据,去重、标准化。
Curator(策展人)基于 Tavily 的相关性评分,筛选高质量内容,过滤噪声。
Briefing(简报生成)用 Gemini 2.5 Flash 生成各维度的初步总结。
Editor(编辑)用 GPT-5.1 整合所有内容,输出最终报告。
整个流程是异步的。用户提交请求后,系统返回一个 job_id,前端通过轮询获取进度。这种设计让复杂的研究任务可以在后台慢慢跑,用户不用盯着屏幕等。
报告输出支持 Markdown 和 PDF 两种格式。PDF 版本用自定义 CSS 渲染,排版专业,可以直接放进投资备忘录。
和 GPT Researcher 有什么区别?
说到这里,你可能会问:市面上不是已经有 GPT Researcher 了吗?这个工具有什么不一样?
这是个好问题。两者确实有不少相似之处:都是多智能体架构,都用 Tavily 做搜索,都输出研究报告。但定位完全不同。
GPT Researcher 是通用框架,像一把瑞士军刀,什么都能切,但什么都不是最顺手。它的优势是社区大、生态成熟、GitHub 14K+ star,你可以用它研究任何话题,从”量子计算原理”到”2026 年 NBA 季后赛预测”。
Company Research Agent 是垂直工具,像一把手术刀,专门为公司尽调设计。它的优势是精确、可控、针对性强。
关键差异体现在几个方面:
GPT Researcher 定位通用研究框架,Company Research Agent 定位垂直领域工具。
GPT Researcher 的实体识别是基础处理,Company Research Agent 用 Grounding 加聚类。
GPT Researcher 用单一模型,Company Research Agent 用双模型分工。
GPT Researcher 适用场景广泛但浅,Company Research Agent 狭窄但深。
GPT Researcher 是开源自托管,Company Research Agent 是官方 SaaS。
这不是谁好谁坏的问题,是场景选择的问题。
如果你要快速了解一个新行业,GPT Researcher 更合适。但如果你要投资前尽调一家公司,Company Research Agent 的精确度会让你更放心。
为什么 Tavily 愿意官方上线?
2025 年底,Guy 把这个项目发给了 Tavily 的创始团队。
他没有做 PPT,没有写商业计划书,只发了一个 GitHub 链接,和一份 5 分钟就能看完的 Demo 视频。
两周后,他收到了回复:“我们把这个上线吧。”
Company Researcher 以官方产品的形式,部署到了 companyresearcher.tavily.com。
Tavily 为什么愿意投入资源?
产品契合度极高。Tavily 的核心业务是 AI 搜索 API,服务开发者。但开发者用 Tavily 能做什么?需要一个具体的场景来展示。公司研究就是一个完美的 showcase,足够复杂,能体现 Tavily Search 和 Extract 的协同能力;又足够通用,几乎所有行业都用得上。
技术验证价值。Grounding 机制、双模型架构、多智能体流水线,这些设计理念可以被 Tavily 抽象成通用的 best practice,输出给其他开发者。Company Researcher 成了一个活的技术文档。
市场时机刚好。2025 年是 AI Agent 的爆发年。从 OpenAI 的 Operator 到 Anthropic 的 Computer Use,从 AutoGPT 到 CrewAI,所有人都在讨论 Agent 能做什么。Tavily 需要一个具体的、可落地的产品,来证明自己在 Agent 生态中的位置。
Guy 的 side project,恰好踩在了这个时机的节点上。
给普通开发者的启示
看完这个故事,你可能会想:我也可以做一个 side project,然后被公司收编吗?
有可能,但有几个前提。
解决真实痛点。不是”我觉得这个很酷”,而是”我自己每天都在用这个”。Guy 做 Company Research Agent,是因为他自己做尽调很痛苦。从真实场景出发的产品,才有持续迭代的价值。
技术选型要务实。LangGraph、Gemini、GPT-5.1、Tavily,这些都不是最新的、最火的技术,但组合在一起,恰好解决了问题。不要追新,要追合适。
保持开源心态。Guy 从一开始就把代码开源在 GitHub 上。这不是慷慨,是策略。开源让你获得早期反馈,建立社区认知,也给了公司一个”试用”你的机会。
选对时机。2024 年做 AI Agent,可能太早,市场不成熟;2026 年做,可能太晚,竞争太激烈。2025 年,是 Agent 从概念验证走向实际应用的转折点。Guy 恰好在正确的时间,做了正确的事。
2025 年,你应该做一个什么样的 Agent?
如果你现在想开始做一个 Agent 项目,我的建议是:找一个你熟悉的小场景,做深做透。
不要试图做一个”通用 AI 助手”,那个赛道已经被大厂占了。也不要追热点做”AI 写代码""AI 做 PPT”,竞争太激烈。
想想你每天工作中,有哪些重复、枯燥、耗时的任务。也许是整理会议纪要,也许是写周报,也许是分析竞品动态。这些小而具体的场景,才是 side project 的最佳起点。
Guy Hartstein 的故事告诉我们:一个解决真实痛点的小工具,可能比一个大而全的平台更有价值。
Tavily 官方上线的不是一个”AI 搜索平台”,而是一个”公司尽调工具”。
你去 companyresearcher.tavily.com 体验过吗?
如果还没试,建议你现在就去搜一家你感兴趣的公司。看看 AI 能不能在五分钟内,给你一份像模像样的研究报告。
然后告诉我:你会做一个什么样的 Agent?
在评论区聊聊你的想法,点赞最高的三位,我送一份《2025 AI Agent 开发资源包》。
(完)
