
跟 AI 聊天最扫兴的时刻是什么?
聊着聊着,它突然来一句:「你刚才说的是什么?」你甩过去一份 100 页的行业报告,它「吭哧吭哧」读完,你追问某个细节,它一脸茫然:「这段内容在输入里没找到。」
问题不在 AI 笨,是它的「记性」太差。
市面上的大模型,上下文普遍 8K 到 128K。8K 装一篇长文,128K 塞一本薄书。听着够用,实际用起来——翻译技术手册得切成十几段,分析财报要分批投喂,聊久了它就把前面的事忘得一干二净。
4 月 24 日,DeepSeek V4 来了,直接宣布:百万字上下文,以后是标配。
这不是简单的「硬盘扩容」,是底层架构彻底换了一套玩法。你的工作流可能要变天了。
一、核心技术突破:不只是装得下,还要跑得动
有人问了:「100 万字?我又不会真扔 100 万字给它。」
但问题的关键从来不是「装不下」,是「跑不动」。
想象一个人背着大包跑步。包越重,跑得越慢,最后喘得跟拉风箱似的。大模型也一样——上下文越长,算得越多,回得越慢,钱烧得越快。所以以前的「长文本」要么是阉割版,要么贵得肉疼。
V4 的突破是换了一种「跑法」。
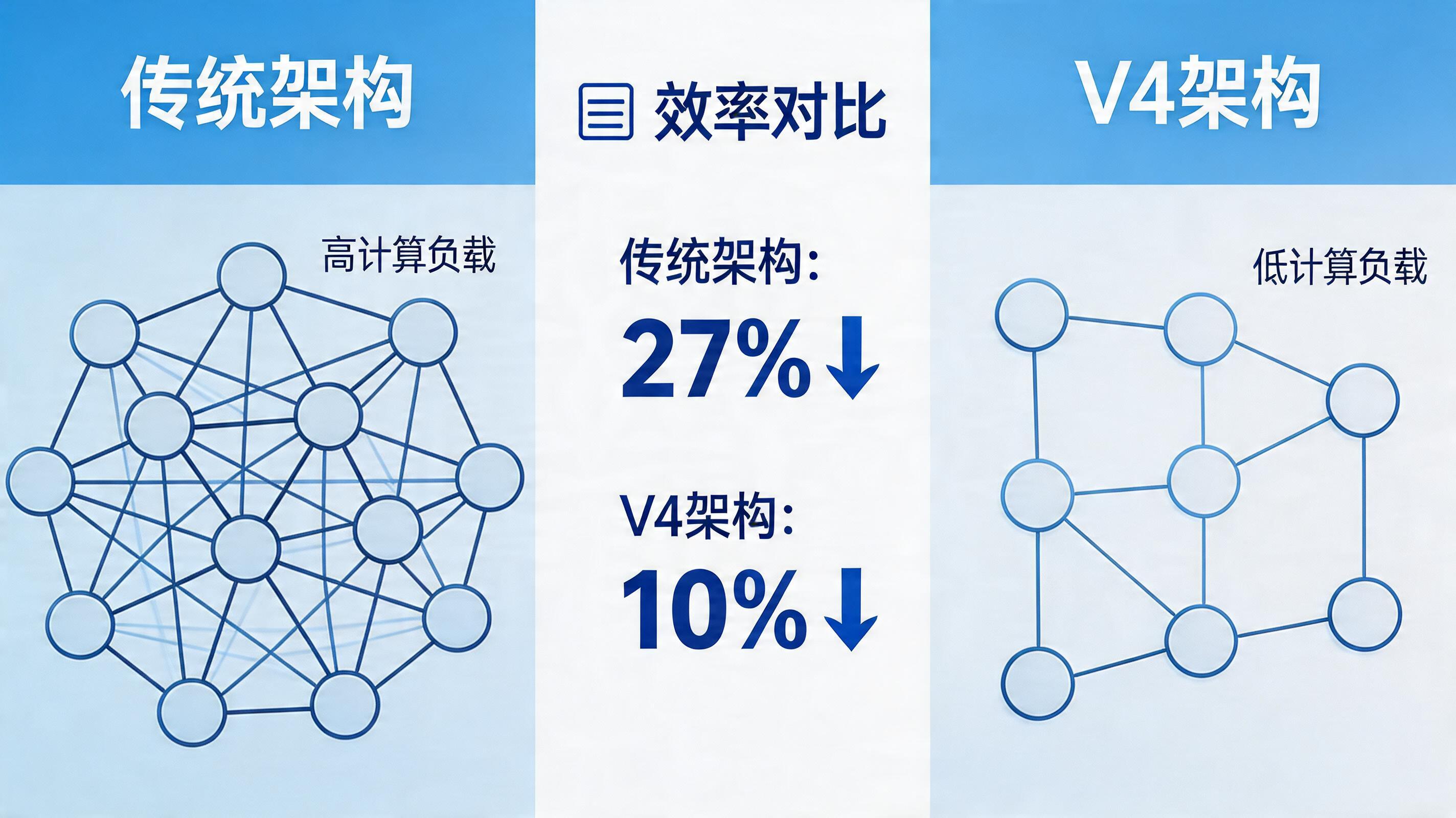
CSA + HCA:给大模型装上「智能筛选器」
CSA(压缩稀疏注意力)+ HCA(重度压缩注意力),听着唬人,其实原理不难懂:
以前的大模型读长文,像逐字精读,每个字都过一遍脑子,能不慢吗?
V4 的做法是先看目录,再挑重点读。它先把长文压成「要点索引」,算的时候只盯关键部分,其他的塞进「外挂记忆」里备用。
效果挺吓人:
- 百万上下文场景,单 token 推理计算量只有 V3 的 27%
- KV Cache(工作记忆)占用只有 V3 的 10%
说人话:以前读完《三体》得耗 10 块电池,现在 1 块都用不完。还更快、更便宜。
这才是「普惠」的意思——不是秀肌肉说「我能做」,而是普通人真用得起。
二、双版本怎么选?
V4 这次出了两个版本,Pro 和 Flash。
V4-Pro:总参数 1.6T(激活 49B),输入 $0.30/百万 token,输出 $0.50/百万 token。旗舰定位,开发者、复杂编程、Agent 场景首选。
V4-Flash:总参数 284B(激活 13B),输入 $0.14/百万 token,输出 $0.28/百万 token。性价比高,日常问答、内容总结够用。
两个版本都支持 1M 上下文。
有意思的是,实测里 Flash 在简单任务上表现不输 Pro。技术圈有句话:最好的不是最强的,是最合适的。
三、五个实测好用的场景
百万上下文到底能干啥?我测了几天,挑了五个最实用的。
读完整本书还能聊细节
《三体》三部曲 90 万字左右。以前想让 AI 帮忙梳理人物关系、分析伏笔,只能分段投喂,聊着聊着它就忘了前面说了啥。
现在整本书直接扔进去,问「章北海的动机是什么?」「黑暗森林法则埋了哪些伏笔?」AI 能基于全书内容给出连贯分析。实测读完三部曲大概 54 万 token,成本不到两块钱人民币。
财报合同一键分析
投行、法务、HR 经常对付几十上百页的文档。以前得自己先读一遍,再挑重点喂给 AI。
现在整份年报直接上传,问「现金流风险在哪?」「这个违约条款和行业惯例比怎么样?」AI 能跨页引用、对比分析,还能指出你漏看的细节。
代码仓库级编程助手
开发者可能最喜欢这个功能。
以前的 AI 编程助手只能看单个文件,让它改功能,它可能不知道这个功能在别的文件里怎么被调用。现在整个项目代码库丢进去,让它分析架构、找 Bug、重构,甚至写跨文件的修改方案。
官方测试里,V4-Pro 的 Agentic Coding 已经是开源模型最强,内部员工说体验比 Claude Sonnet 4.5 还好。
个人知识库
把过去 5 年的笔记、会议纪要、项目文档全喂给 AI。之后问「我去年做过类似项目吗?当时卡在哪?」「某某客户最在意什么?」
不是科幻,V4 的百万上下文已经能撑起这种「长期记忆」。
长视频播客快速消化
2 小时会议录音转文字大概 3-5 万字,10 期播客汇总可能超 20 万字。直接丢给 V4,让它总结要点、提取金句、对比嘉宾观点。
内容创作者、研究员、学生的效率神器。

四、实测体验:亮点与坑
我用 V4-Pro 测了几天,说几句实在的。
确实强的地方:
编程体验超预期。让它写个命令行工具管新闻线索,从需求分析到代码生成一步到位,结构清楚,注释也到位。
长文本理解稳。测了 30 万字的行业报告,跨章节引用准,没出现「幻觉」瞎编内容。
结构化输出靠谱。JSON、Markdown 表格、固定格式整理,执行得都很稳。
要注意的坑:
服务稳定性。V4-Pro 目前算力吃紧,高峰期会「服务器繁忙」。官方说下半年昇腾 950 超节点量产后会缓解。
Flash 版质量参差。角色扮演、创意写作这些场景,Flash 明显不如 Pro,回答有点「机械」。
没有原生多模态。V4 目前只支持文本,图片视频处理不了。要分析 PPT、网页截图,还得等后续版本。
五、怎么用上?
网页版:chat.deepseek.com,免费,基础功能已支持 V4。
手机 App:iOS / Android 应用商店,已更新到 V4。
API 调用:api-docs.deepseek.com,model 参数改成 deepseek-v4-pro 或 deepseek-v4-flash 就行。
开源下载:Hugging Face,Apache 2.0 协议,可以商用。
价格:V4-Pro 的 API 价格大概是 GPT-5.4 的 1/10 到 1/30,Claude Opus 4.6 的 1/30 到 1/150。高频调用的开发者和企业,这个差价能改变成本结构。
六、写在最后
百万上下文不是炫技,是基础设施升级。
AI 从「短期记忆」进化到「长期记忆」,从「逐段处理」到「全局理解」。对普通用户来说,这意味着 AI 真能当你的「第二大脑」——记住你说过的一切,在海量信息里找关联,陪你完成以前搞不定的长周期任务。
DeepSeek V4 的意义不在跑分多高,在它让这种能力用得起、用得上。
长文本时代来了。
你最想用百万上下文做什么?评论区聊聊。
本文部分数据来自 DeepSeek 官方公告、HuggingFace 及实测。价格和功能以官方最新版为准。
