
你有没有这种经历?
开了个Claude Code会员,满怀期待地让它帮你重构项目。三小时后,它交上来一堆代码——能跑,但架构混乱、命名随意、测试覆盖率归零。你叹了口气,还是自己重写吧。
这不是个例。
GPT-5.4、Claude 4.7、Gemini ……模型越来越强,但很多人发现:AI写的代码,质量依然靠运气。今天神勇,明天翻车。同一个提示词,两次输出天差地别。
问题不在模型。
是你缺了一样东西——Harness。
Agent 不是什么
现在「AI Agent」这个词,已经被一大批做提示词、搭流程的圈子彻底玩坏、滥用了。
各种拖拽式无代码平台、AI 工作流工具、提示词串联库,全都在蹭 Agent 的概念。
它们有个共同的误区:
只要把大模型 API,用判断分支、流程图、固定规则硬拼在一起,就叫 AI Agent 了。
根本不是。
这类东西本质就是过度复杂、一碰就崩的固定流程流水线,大模型只是被塞在里面,当个高级点的文字填空工具而已。
这根本不算智能体,顶多就是包装得花里胡哨的脚本命令。
这种拼拼凑凑做出来的 “Agent”,是不会写真正模型、不懂 AI 本质的人的空想。
他们只会靠堆固定流程、复杂规则、一层层套提示词,想用纯工程拼接的方式,硬生生 “凑出” 自主思考和主动能力。
但现实就是:自主性、真正的智能,是模型学出来的,不是靠代码和规则硬写出来的。
这类流水线式 Agent 从做出来的那一刻就注定不行:
极度脆弱、没法扩展、完全没有举一反三的泛化能力。
说白了,就是几十年前早就被淘汰的「老式符号规则 AI」换了层 LLM 皮,重新炒冷饭。
换了个新名字,换了层包装,走的还是当年那条走不通的老路。
模型是马,Harness是缰绳

先说清楚一个概念。
“Harness”原意是马具。缰绳、马鞍、马镫那一套。再烈的马,套上Harness才能拉车、耕地、上战场。
AI Agent也一样。
模型是马——提供动力、速度、爆发力。GPT-5.4、Claude这些大模型,就是训练出来的”千里马”,见过 billions 行代码,推理能力惊人。
Harness是马具——决定马往哪跑、跑多快、能不能停下来。没有Harness,马再快也只是原地打转。
用公式说就是:
Agent = Model + Harness
模型负责”想”。Harness负责”做”——把想法变成可执行的行动,在真实环境里完成任务。
裸模型有四个硬伤:
- 记不住昨天说了啥(无跨会话记忆)
- 写完代码没法自己跑(无执行环境)
- 不知道昨天发布的API怎么用(知识有截止日期)
- 不会自己创建文件、管理项目(无工作环境)
Harness就是来补这四个窟窿的。
Harness的六大核心组件
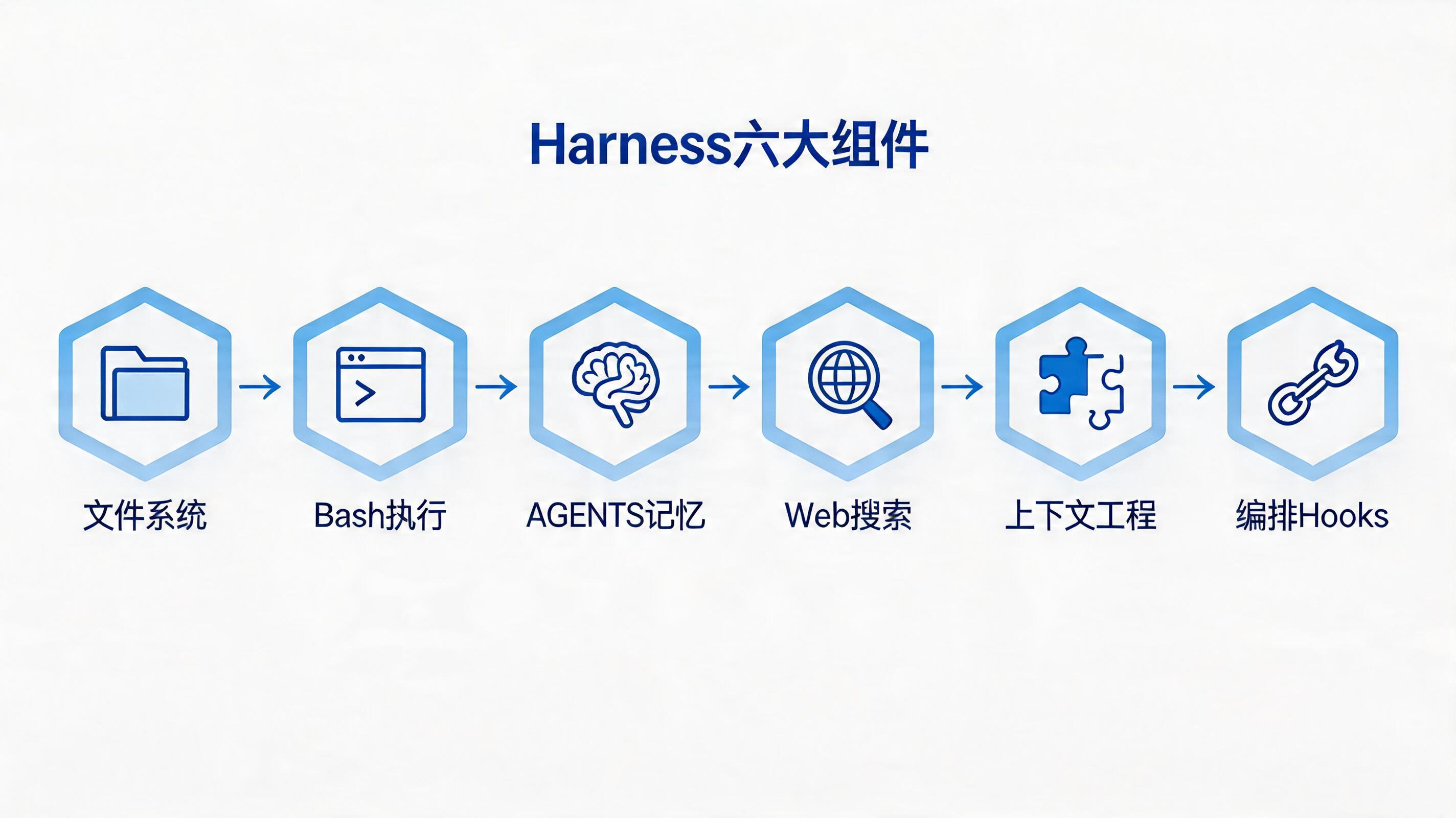
一套完整的Harness长什么样?六个组件,各司其职。
1. 文件系统——工作台
最基础,也最容易被忽略。
Agent需要地方存代码、写日志、记中间结果。文件系统就是它的”外部大脑”——突破上下文窗口的唯一途径。
更重要的是版本控制。配合Git,Agent可以大胆试错:改坏了?回滚。实验失败?丢弃分支。这种”试错自由”是创造力的前提。
2. Bash + 沙箱——手和脚
裸模型能”写”代码,但不能”跑”代码。
Bash环境让Agent真正动手:运行自己写的代码、安装依赖、执行测试、看报错、修bug。形成一个”写→跑→看→修”的自我验证闭环。
实测数据:有自我验证能力的Agent,任务完成率比”一次性生成”高出40%-60%。
当然,要加沙箱。你不能让Agent随便执行rm -rf /。资源限制、网络隔离、超时机制——安全是Bash能力的前提。
3. AGENTS.md——长期记忆
模型有个尴尬的问题:每次对话都是全新的开始。
昨天讨论的架构方案?忘了。你反复强调的编码规范?忘了。Agent踩过的坑、学过的教训?统统归零。
AGENTS.md是个活文档,放在项目目录里。Agent工作时把新知识写进去,下次启动自动读取。
本质是不改模型权重,只通过上下文给模型加知识。今天发现一个新坑,写进去,明天Agent就记住了。不需要微调,不需要等模型更新。
4. Web Search + MCP——感知外界
模型有知识截止日期。昨天发布的框架、上周更新的API、今天的新闻?它不知道。
Web Search打开这扇门。Agent能搜索最新资料,打破”时间牢笼”。
MCP(Model Context Protocol)更进一步。它是Anthropic推出的”AI世界的USB接口”——数据库、内部Wiki、项目管理工具、监控系统,只要有MCP接口,Agent就能直连。
修Bug时,Agent可以同时查日志、看代码、搜社区讨论、检查已知问题列表。像个经验丰富的SRE。
5. 上下文工程——注意力管理
上下文会”腐烂”。
对话越长,堆积的信息越多:早期指令、中间讨论、工具输出、错误日志……信噪比持续下降。模型开始”变笨”——遗忘约定、重复错误、前后矛盾。
上下文工程就是对抗这种”熵增”:
- 压缩:把冗长历史摘要成要点
- 卸载:大段输出存文件,上下文只留引用
- 分层:核心信息常驻,临时信息按需加载
关键洞察:上下文利用率有个甜蜜区间。用到40%左右效果最好,超过就开始走下坡路。给Agent塞满MCP工具、长篇文档,不会让它更聪明——反而会让它变笨。
6. 编排 + Hooks——团队协作
复杂任务需要多Agent协作。
编排解决”谁做什么”:任务怎么拆、依赖关系是什么、哪些并行哪些串行。DAG编排、动态编排、层级编排——模式取决于任务复杂度。
Hooks是质量守门员。代码生成后自动跑Linter、格式校验、安全审查。用确定性规则约束概率性输出。
概率生成 + 确定性校验,这是目前Agent工程最有效的质量保障策略。
OpenAI的百万行代码实验
理论说完,看个真实案例。
2025年底,OpenAI做了场实验:3名工程师,用5个月,通过AI Agent开发了约100万行代码。
约束条件:零手写代码。所有代码必须由Agent生成。
结果:合并了约1500个PR,每人每天产出3.5个PR。效率提升约10倍。
他们总结的核心经验就一条——瓶颈不在模型智能,而在Harness设计。
五个具体做法:
-
设计环境,而非编写代码。Agent卡住时,不替它写,而是诊断”缺什么能力”,让Agent自己构建。
-
机械化执行架构约束。定义模块依赖方向,用自定义Linter自动检测违规。文档记录是不够的——“如果不能机械化执行,Agent就会偏离”。
-
代码仓库是唯一事实源。Slack讨论、Google Docs对Agent等于不存在。所有知识必须版本控制在仓库里。
-
连接可观测性。给Agent浏览器自动化工具,让它能像用户一样做端到端测试。
-
对抗熵增。每周花20%时间清理”AI Slop”(低质量生成物),后来自动化为后台Agent任务。
最妙的是他们的Linter设计:报错信息不仅标记违规,还告诉Agent怎么修复。工具在工作时”顺便教学”。
写给Harness工程师
如果你在使用AI写代码,你已经是个Harness工程师了。
只是很多人没意识到,还在错误的地方使劲——换更强的模型、写更复杂的提示词、买更贵的会员。
方向错了。
真正该投入的是Harness:
- 你的项目有AGENTS.md吗?
- Agent能自己跑测试吗?
- 有自动化的代码检查吗?
- 上下文管理有策略吗?
三件事,今天就能做:
- 在项目根目录建个AGENTS.md,把团队规范、常见坑、架构决策写进去
- 给Agent配个带沙箱的Bash环境,让它能自验证
- 加一个简单的Linter或类型检查,自动拦截明显错误
模型会继续进步,但进步速度在放缓。Harness的工程空间还远没被挖掘。
你就是Harness的一部分
最后回到那个公式:
Agent = Model + Harness
如果你不是模型本身——那你就是Harness的一部分。
你写的System Prompt、搭的工具链、设计的记忆机制、优化的上下文策略、编写的Hook规则……全都在定义Agent能走多远。
OpenAI那3名工程师,5个月产出的不只是100万行代码。他们验证了一件事:模型提供下限,Harness决定上限。
下一次AI让你失望时,先别急着换模型。
看看你的Harness。
