
今天,火山引擎的方舟Coding Plan悄悄上新了。
GLM-5.1、Kimi 2.6、MiniMax M2.7——三款国产大模型齐刷刷上线,套餐价格还是熟悉的配方:Lite版40元/月,Pro版200元/月。看着挺香,对吧?
结果用户不买账。
V2EX上一个帖子,28条回复里至少一半在吐槽。有人直言”隐藏倍率,狗都不买”,有人说”试完你就不会再想买了”。客服群更是”高强度被骂了一天”。
问题出在哪?
慢,是真的慢
一位Pro套餐用户反馈:用GLM-5.1,首字响应要30秒以上。
什么概念?
你敲完代码,端着咖啡等它回复,咖啡都凉了,屏幕还在转圈圈。
更离谱的是这位:“我用K2.5模型,3分钟输入了103个token,像掉线一样。Trae免费的K2.5排完队都比它这个plan快。”
3分钟,103个token。
这速度,手工打字都比它快。

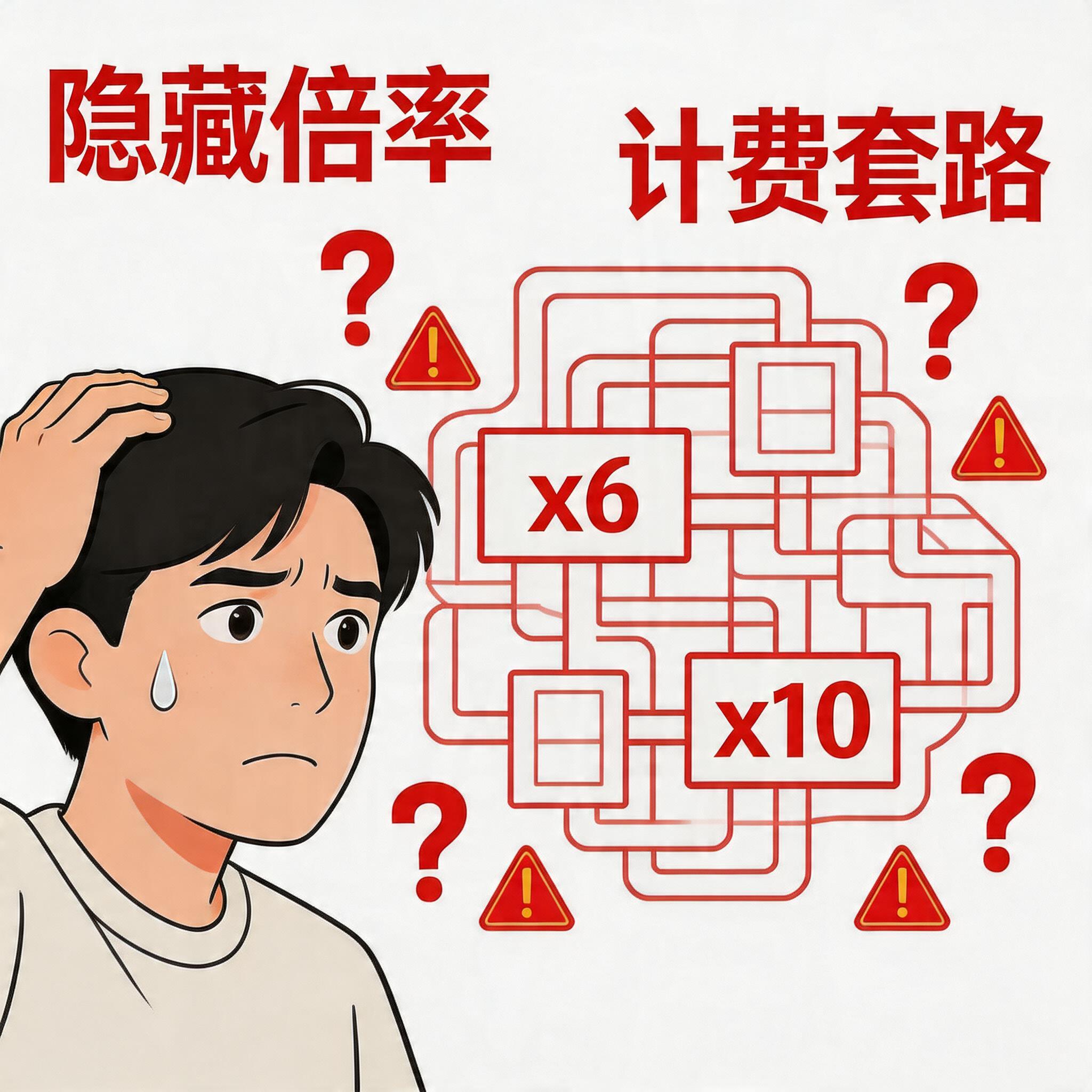
隐藏倍率,玩得花
火山方舟的Coding Plan主打”按次计费”,听起来很简单——买个月卡,随便用。
但用户实测后发现,事情没那么简单。
“火山隐藏倍率,动不动就*6、*10,比某些丧良心的中转站都黑。”
有人用脚本测试:如果每次请求7-10万上下文,每5小时只有100次左右的额度。全月算下来,也就500次左右。
只有每次5000左右上下文,才能达到宣传里的”每小时1000次”。
一位用户总结得精辟:
“看似Coding Plan,实则Token Plan。Token用少了按次数限制,Token用多了按Token限制——横竖都是赚。”
这宣传,确实有点 misleading。
模型”变蠢”了?
还有用户发现,同样的模型,火山版的就是比官方版”蠢”。
“我以前一直以为GLM蠢,后来发现只是火山版的比较蠢。”
另一位用户说得更直接:“它家的模型又慢又蠢,量化过度了。”
量化,是为了降低计算成本、提高推理速度的常用手段。但过度量化,模型的能力就会打折扣。
大厂补贴战打得火热,价格一降再降。但羊毛出在羊身上——成本压下来了,体验也跟着缩水。
客服群被骂了一天
一位知情用户透露:“客服群高强度被骂了一天。”
想想也是。用户满怀期待买了套餐,结果速度慢得像蜗牛,计费规则还藏着掖着。换谁不生气?
有人直接选择了退款。
也有人表示:“值是挺值的,但是楼上说完之后我有点不想买了。”
口碑崩塌,就是这么快。
大厂补贴战的代价
火山引擎不是第一家,也不会是最后一家。
从大模型竞赛开始,价格战就没停过。今天你家首月8块9,明天我家免费送额度。用户看得眼花缭乱,厂商打得头破血流。
但补贴战的终局是什么?
资源有限,用的人越多,体验越差。为了控制成本,要么限流排队,要么过度量化。最后受伤的,还是用户。
一位用户说得在理:
“资源有限,用的人越多体验可能越差。想白嫖的抓紧,手慢无。”
但问题是,Coding Plan不是白嫖,是付费服务。付了钱还得”手快”,这合理吗?
用户要的是什么?
说实话,开发者对大模型的要求并不高。
够快——别让我等半天。 够准——生成的代码能用。 够透明——计费规则清清楚楚,别玩套路。
就这三点。
火山引擎今天的上新,看似给了用户更多选择。但如果底层体验没跟上,模型再多也是白搭。
一位买了两个月Pro套餐的用户,昨天刚过期没续费。结果今天火山就更新模型了。
他说:“不过就算它更新模型我也不想续了。”
你看,用户一旦失望,再拉回来就难了。
写在最后
大模型赛道正在从”拼参数”转向”拼体验”。
benchmark再好看,用户用着卡顿,也是零分。价格再便宜,服务跟不上,也是负分。
火山引擎今天这波上新,本可以是个好消息。但看来,他们还需要在”体验”这两个字上,多下点功夫。
毕竟,用户的耐心是有限的。
骂娘的声音,服务器那头,真的能听到吗?
